

Hi everyone!
We’re going today to dive into one of the most terrible things developers & marketers have to handle together: installing “pixels” on a website.
On one hand, we all know they’re crucial:
to understand your traffic
which ads brought which conversion
to learn more about user behaviors (heatmaps, recordings)
But you also probably know that things are changing and that pixels, as we know them, are having hard times in 2022…
→ I’ve literarily seen HUGE gaps between data collected by pixels/scripts and the real figures of a company.
For instance, if you have a Shopify website: you can compare the number of orders you received last month in your Shopify back-office with the number of conversions you have in Google Analytics.
To give you an idea, it’s rather common to see 30% TO 60% GAPS BETWEEN BOTH!!
However, many companies still rely on inaccurate, front-end pixel data to drive their business.
That’s why this subject is so important. If you make decisions based on data that is 30-60% inaccurate, you’re probably losing big.
Surprisingly, there are not many resources about this around the web — or they are incredibly misleading, or hard to understand: server-side tracking, server-to-server, backend-tracking, reverse-ETLs… Easy to get confused.
That’s why I am writing this article today.
I want to bring you easy-to-understand solutions. We’ll discuss the 3 commons “levels” of tracking.
If you’re spending money on paid ads, or just want to have your numbers as close as possible to reality, this article is for you!
Here’s what we’ll cover in this article:
Level 1: Client-side tracking
Level 2: server-side tracking (but there is a catch…)
3. Level 3: Back-end tracking (& reverse-ETLs)
Enjoy!
Why it matters:
Do I really need to explain again why data is important?!
Let me just give you a quick example. Let’s say you’re an eCommerce running Facebook ads.
Your target CAC is $8.5 per conversion.
You’re currently running ads. You have 100 conversions every time you spend $1000 on Facebook.
OK. That’s a $10 CAC. You’re not profitable.
But now let’s say you have 30% more conversions brought to Facebook thanks to a better tracking setup.
You now have 13 conversions for every $100 spent. That’s a $7,69 CAC.
Then you are profitable.
Basically, these kinds of changes can have a massive impact on how you understand your business and the channels you decide to kill or scale.
Now, let’s have a look at the 3 different ‘levels’ of tracking. From the worst best!
Level 1: Client-side tracking
The 1st and most common type of tracking is the client-side.
The “client” is simply a browser: Chrome/Safari, mobile/desktop…
When we speak about “client-side” tracking, it means that the pixels and scripts are installed directly on your website.
→ Visitors load the little Facebook JavaScript snippet when they load a page on your website.
Benefits:
As you can guess, installing those scripts on the client is really easy. You basically have to copy and paste a little code snippet into your website, like this one:

Or to add it into your Google Tag Manager container (which is also loaded
on the client side, and then will load everything on the client as well).
But this is where you’re going to have some troubles:
Government regulations (GDPR, CCPA…) require you to be transparent, understand what data you collect, and ask your users’ contentment for data collection/usage
With pixels directly installed on your website, you don’t really know what’s going on.
3rd parties (such as Facebook) might collect more data than needed. They’re installed for sure, but you don’t have control over the data flows, which kind of data is shared, how…
More and more users use ad blockers: those users won’t load those pixels, and you’ll get inaccurate data.
More and more browsers themselves are having an impact on those pixels*.
How client-side tracking works:

*I won’t go into the details for today on how browsers impact client-side pixels because this is where it gets extremely confusing. This could be an entire article.

For instance, Safari will tell you it has ‘prevented trackers from profiling you’ but the reality is that it has only an impact on 3rd party cookies.

However, scripts like Google Analytics haven’t been using 3rd party cookies for a while. They set cookies on your own domain (green arrows below).

But still, as you can see in red, Safari has an impact on those ‘known
trackers’ as it forces cookies to expire 7 days after the session started.
Basically, it’s a cat and mouse game — and a whole mess. 🤯
(We only spoke about Safari here, but each browser has its rules. If you want to learn more about this you can check this blog, and cookiestatus).
All you have to remember is that client-side tracking is not reliable anymore (and probably makes you lose money).
That’s why you might want to switch to Level 2 of tracking…
Level 2: server-side tracking (but there is a catch…)
So here we are. You’ve probably heard of this recently too — as the magic solution to all of our client-side tracking problems.
How does it work:
When you visit a website, things happen on your browser (client-side) but you also load elements from a server:
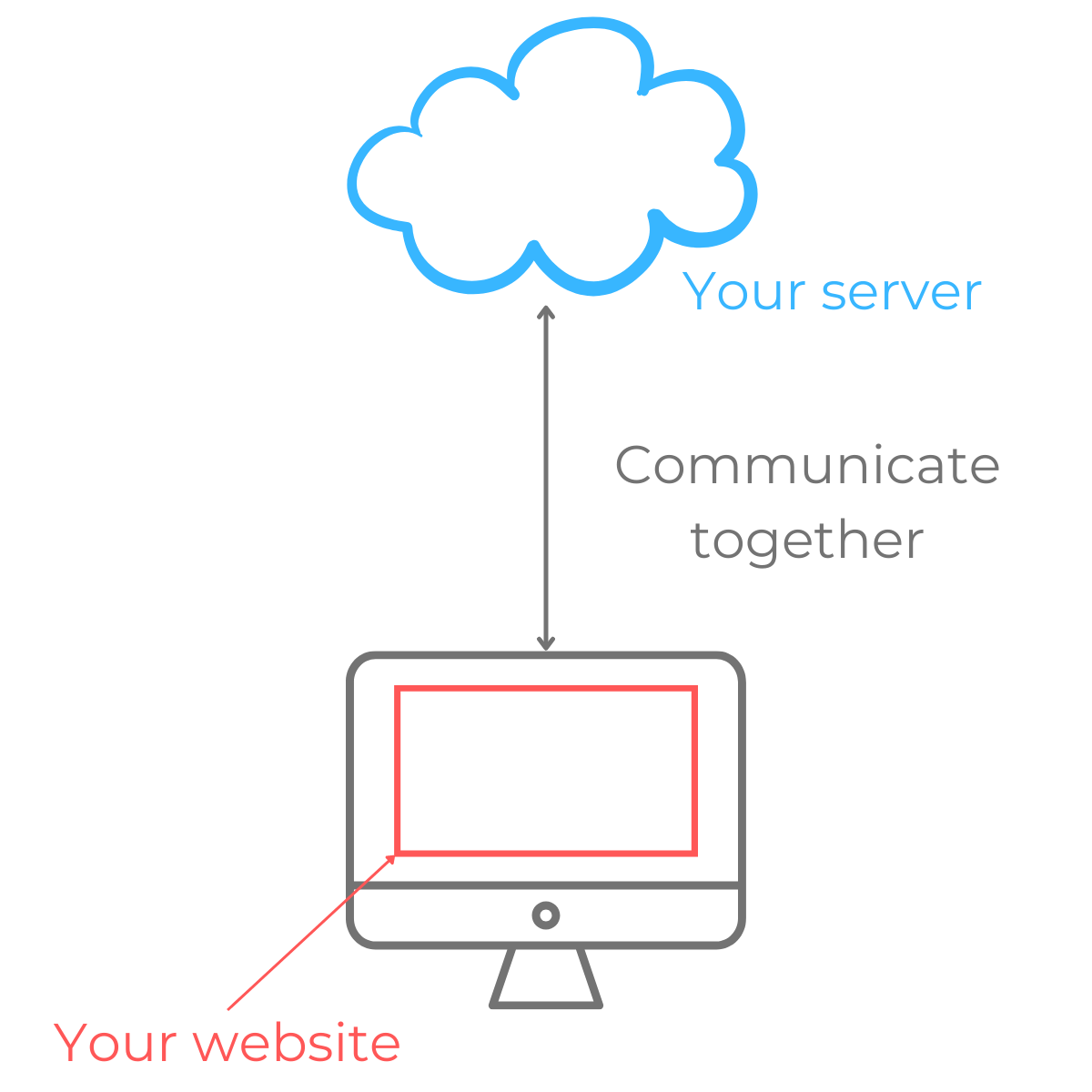
So the idea behind server-side tracking is to send data from your server to 3rd party servers.
Your ‘pixels’ are not loaded on the client-side anymore.
By the way, we don’t even talk about ‘pixels’ anymore. You just send data from your server to others, using APIs.
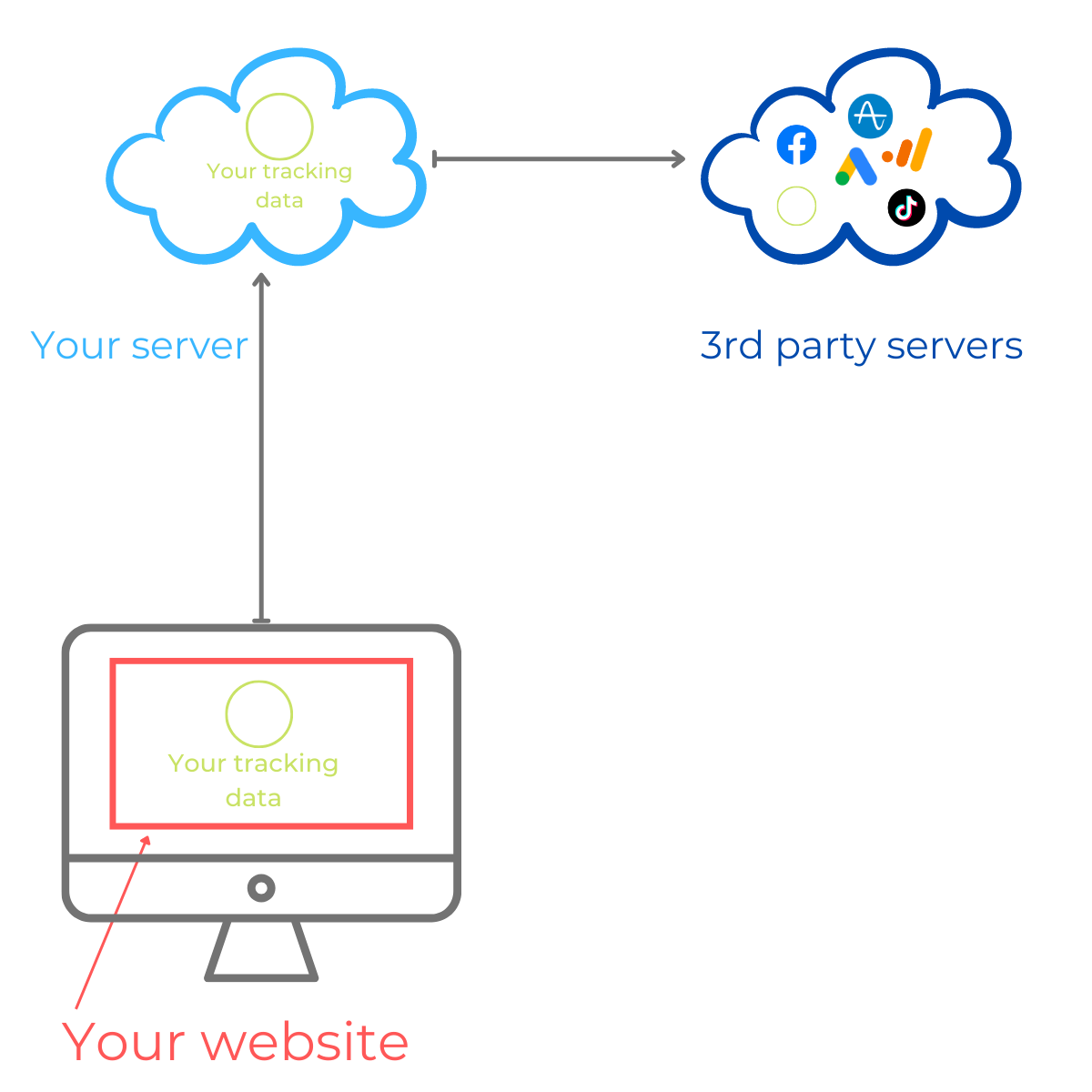
Example:
For instance, if you visit Ulysse, you won’t be able to notice that they use Amplitude: the script is not loaded on the website and doesn’t add any cookie to your device.
That’s because Ulysse uses a server-side tracking setup through Rudderstack:
Rudderstack is loaded on the website
Then sends data to Ulysse’s Rudderstack server
Then this data is sent to Amplitude for Analytics

Benefits:
Using a solution like this, you’ll reduce the problems you have doing client-side tracking:
You have 100% control over what data you send to whom. You exactly know the workflows, as you configured it yourself (Facebook isn’t capable of ‘sniffing’ anything from your website). Thus you can easily comply with regulations like GDPR & CCPA.
You reduce the impact of ad blockers and browsers as you don’t load anything from 3rd parties on your website (any of your cookies is set on your own domain)
Thus you’ll improve data accuracy (and reduce CAC as we’ve seen at the beginning of this article)
Your website is likely to have better performances (lighter/faster) as you don’t load heavy scripts & pixels from 3rd parties anymore (but only yours).
How to get started with server-side tracking (be careful ⚠️)
The most common way to use server-side tracking is to use the Server Side Google Tag Manager.
But this is not easy: 1st, it requires a heavy and hard setup. You’ll probably need a developer to work with you to get started.
Second, Google will charge you for using Google Tag Manager Server side.
There are even solutions that ease this Server-Side Google Tag Manager setup and charge you a bit more: see stape.io as well as Elevar (for Shopify).
Here’s my take on this: please don’t do this. Especially if you’re a B2B SaaS or fintech.
Let me explain.
Server-side GTM collects data… From the client
What server-side vendors often forget to mention is that server-side tracking will always be dependent on the source of data collection.
In other words, Google Tag Manager is still loaded on our website. This could even be named ‘client-to-server’ tracking.

Then (and only then) it sends data to 3rd parties through APIs.
And Google Tag Manager itself can be blocked by ad blockers, browsers, etc…
→ Anyway, you’ll only reduce the number of problems you have doing server-side tracking this way… But not fix everything.
If you’re at that stage, that means you’re ready to invest money, time, and technical resources (i.e: a developer) into this problem.
That’s why I strongly encourage you to go for a Customer Data Platform (such as Segment or RudderStack) instead of focusing on GTM server-side.
Customer Data Platforms in this situation are basically a Google Tag Manager on steroids.
Meaning that: It will do the same job as Google Tag Manager: collect data, and send it to your tools (for both client-side and server-side).
But that’s not it. Customer data platforms guide you to better data practices.
With customer data platforms, you mainly have 2 event types:
Trackevents, which let you track user behaviors, depending on your specific needs.For example, at Ulysse when you search for a flight, a
prebooking_flight_searchedis fired, and it collects data related to the flight you’re searching (origin, destination...).Identifyevents, to collect user information: such as emails, phone numbers, or anything else.Those are helpful to create users into your CRM (Hubspot, Salesforce…) or mailing tools such as Customer.io for instance.
Even though it might be somehow feasible with GTM, you might end up having a harder journey, thus bad data practices… And thus, bad data.
And this is exactly what we want to avoid!
Having the data collection standardized (with track/identify events) enables CDPs to send data pretty much anywhere (and this is exactly their job!).
Whereas you might end up having to create custom pipelines/code for each tool you want to use with GTM server-side.
Finally, there are thousands of destinations to where you can send your data from your CDP.
Much more are available for the server-side (cloud mode) than the few you can find for Server-Side GTM.
Long story short… Having a customer data platform is often the 1st step to good data practices for growth, for not much more cost than a Server-Side GTM setup.
I understand it’s hard to perceive the value if you’ve never seen it before. But believe me, you won’t regret it.
Also, feel free to book me a call if you want to discuss your setup. Happy to help!
3. Level 3: Back-end tracking (& reverse-ETLs)
Or server-to-server tracking
As we’ve just seen, even with a server-side tagging solution, you might depend on a front-end data source: your website.
And this is where customer data platforms are also super powerful: because you can also add back-end sources for your data.
For instance, you can add a Segment/RudderStack Ruby or Node.js source, track everything from your server, and then send it to your tools.
This means that you don’t rely on a front-end data source at all, and thus you can avoid all the browser-related problems — and get closer to the perfect data accuracy in your tools.

But you guessed it, this might be even more complicated to set up.
This time you’ll need to have not only a front-end developer involved but a back-end developer.
Also, it depends a lot on your tech stack. For example, you might not be able to access everything from the back-end if you use an all-in-one solution such as Webflow or Shopify.
That’s why back-end tracking remains pretty rare for now.
Long story short: this is harder — but this is how you get the best data accuracy, and thus drastically improve your performances.
Also, we often end up using not only one of the solutions but a bit of each.
Sometimes, it’s simply not possible to use server-side tracking: for instance, for session recordings tools (Hotjar) or chatbots (Drift) you need to use client-side tracking.
Also, you might prefer using a warehouse and a reverse-ETL for your growth stack: this will enable you to collect and model your data from any source (front, back, tools…) but will require you to have a data team to set everything up.
You can read my previous post about this.
And that’s a wrap!
I did not even mention post-acquisition tracking to keep it as simple as possible for today, but you can imagine that many options are available.
👉 With customer data platforms, you’re able not only to collect event-based data from your website front AND back-end but also from your product, your database, and 3rd-party tools as well…
This will probably be for another post!
See you,
Victor